复杂的拷贝
2016-12-20
Copy
Copy,拷贝,或者复制,看起来挺简单。但它其实并不简单。深入讨论拷贝会触及到编程语言的一些基础问题。这个问题是:“可变,还是不可变?”。它们各有优点。伴随巨大优点的,通常是沉重的代价。同时,我们在选择了一条路之后,特别是在遇到荆棘时,通常会思考:另一条路是不是会更好一些?答案通常并不明显,很多路是无法重新走过的。
下面以 Objective-C 为例,看看拷贝究竟会折射出哪些关于编程语言的更基础的问题?
NSMutableCoying 是一个额外的代价
在讲 NSMutableCopying 之前,先讲讲 NSCopying。对于 Foundation 中的大部分对象,我们都可以使用 [object copy] 获得一个该对象的拷贝。这是因为这些类都实现了一个协议:
NSCopying。这个协议要求你实现一个方法 - (id)copyWithZone:(NSZone *)zone。拷贝有很多种,有拷贝的程度各不一样。这取决于类如何实现 - (id)copyWithZone:(NSZone *)zone。如果,我们实现了一个普通类,那么就可以到此为止了。实现好 NSCopying 协议,提供一个适合该类的拷贝行为就行了。
但是,我们很容易发现 Foundation 中还有一个和 NSCopying 对照的协议: NSMutableCoying。NSMutableCopying 的存在是因为 Objective-C 提供了一系列可变类和不可变类的对象组。例如,NSString 和 NSMutableString,NSArray 和 NSMutableArray。引入这种可变和不可的对照类的原因是,不可变对象有着诸多好处。例如,不用担心副作用,内存开销小,线程安全等。而且很多场景下,确实并不需要对象是可变的。这时使用不可变对象就有着诸多实际的好处。
但 Objective-C 本质上还是一个面向对象的命令式的编程语言。以可变的对象表达状态的变化是这一编程范式的基础建模方式之一。所以,在 Objective-C 中,可变对象仍然是必须的。那么,因为不可变对象有诸多好处,在为可变对象提供了对应的不可变的版本之后,就还需要为可变版本的对象和不可变版本的对象之间的转换做一些额外的事情。NSMutableCopying 就是因为需要这种转换而产生的。
NSMutableCopying 只有在你提供了一个可变和不可变类对照组的情况下,才需要使用到。它用于表明对象可以返回一个可变版本的拷贝。以字符串类的对照组为例:
- 对一个不可变的 NSString 对象调用方法
mutableCopy将得到一个可变的 NSMutableString 类型的对象; - 对应的,对一个可变的 NSMutableString 类型的对象调用方法
copy将得到一个不可变的 NSString 类型的对象。
这就是 NSMutableCopying 和 NSCopying 两个协议在不可变的 NSString 和可变的 NSMutableString 之间建立起转换桥梁的例子。
当然,如果,没有可变和不可变的区分时,NSMutableCopying 这个协议是不需要的。大多数情况下,我们自己编写的类都是这种情况:实现好 NSCopying 即可,无需管 NSMutableCopying。
但 Foundation 中很多类是我们使用 Objective-C 的基础。这些类对于性能,安全有着更高的要求。不变性正好提供了这方面的好处。那么,提供一个不可变的版本是有必要的。但是,提供了不可变版本之后,可变版本和不可变版本之间的转换又是一个额外的工作。
所以,NSMutableCopying 是在一门可变的语言中追求不可变性的一个代价。它是必要的,但它使得事情变得更复杂了。
NSCopying 也是一个额外的代价
本质上,一个不可变对象是不需要拷贝的。因为,无论你持有了不可变对象本身,还是持有了不可变对象的拷贝,如果有了不变的保证,在任何情况下,使用两个对象中的任何一个都是没有区别的。
这在 Foundation 中,对不可变对象的拷贝行为的实现中也有体现。我们运行如下两行简单的代码:
NSArray *array = @[@"1", @"2"];
NSArray *arrayCopy = [array copy];
打个断点,看看他们内容和地址。可以发现它们的内容和地址都是一样的。也就是说两个变量是指向同一个对象的指针。
// array
Printing description of array:
<__NSArrayI 0x60000003eaa0>(
1,
2
)
// arrayCopy
Printing description of copy:
<__NSArrayI 0x60000003eaa0>(
1,
2
)
所以,可以推断 NSArray 对 NSCopying 协议的实现只是简单地返回了其本身。可能就像下面代码一样:
- (id)copyWithZone:(NSZone *)zone {
return self;
}
这个例子揭示了一个不可变对象无需拷贝。拷贝是由于在编程语言中引入了可变量这一概念,而带来的副产品。可变隐含了时序概念:变量在某个时间点是一个值,在另一个时间点是另外一个值。拷贝其实是对变量所隐含的时序的一种描述。拷贝的意思可以翻译为这样一段描述:“我需要拷贝的那一刻的值,然后,对这个变量之后的变化不感兴趣。”
所以,拷贝是可变的一个额外的代价。对于 Objective-C 这类以可变量为基础的编程语言。拷贝是必须的,但它使得事情变得更复杂了。
拷贝行为没有统一的定义
拷贝本身其实并不简单。首先,我们很难为所有类定义一个统一的拷贝行为。就以 NSArray 这种容器类为例做个说明。如果,数组里都存着 @1,@2 这样简单对象,那么对数组进行拷贝,我们可以很容易达成一致:将这些简单对象也拷一份就可以了。但是,如果数组里存的是很复杂的对象。例如,一个树的结点:
@interface TreeNode : NSObject <NSCopying>
@property (nonatomic, copy) NSString *value;
@property (nonatomic, strong) TreeNode *left;
@property (nonatomic, strong) TreeNode *right;
- (instancetype)initWithParent:(TreeNode *)parent left:(TreeNode *)left right:(TreeNode *)right;
@end
对 value,进行拷贝我们不会有异议。对 left,right 的拷贝,则会陷入一个循环。因为,它们也是 TreeNode 类型,也包含了自己的 left,right。它们的 left,right 是否也需要拷贝呢?这会牵扯出一个巨大拷贝链。对一个树的结点进行“完全的拷贝”,其实就是重建该节点所在的树。
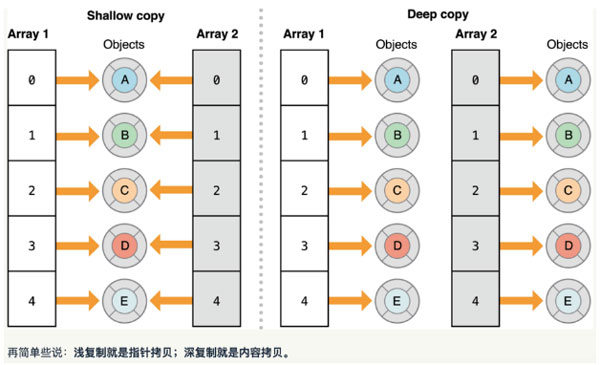
如果,一个很长的数组存储的都是像 TreeNode 这样的对象。完全拷贝这个数组,将会消耗巨大的内存,或者就根本无法完成。基于这个原因,很少有类的拷贝行为会被设计为完全拷贝。一些类的拷贝被设计为浅拷贝。即对被复制对象的实例变量都只进行指针复制。或者,稍微深入一些,做深拷贝,保证对其实例变量进行拷贝。但是,实例变量的实例变量是何种行为则由其自身决定,或者说无法真正控制。
下面,以 TreeNode 为例实现这几种拷贝行为。
Shallow copy,浅拷贝
对于被复制对象的实例变量都只进行指针复制。
- (id)copyWithZone:(NSZone *)zone {
TreeNode *node = [[[self class] allocWithZone:zone] init];
node.value = self.value;
node.left = self.left;
node.right = self.right;
node.isTerminated = self.isTerminated;
return node;
}
One-level-deep copy,深拷贝
对于被复制对象的实例变量,创建新对象,做了真正的对象拷贝。但是更深一层:实例变量对象的实例变量,则取决于不同实例变量对象本身的拷贝行为。
- (id)copyWithZone:(NSZone *)zone {
TreeNode *node = [[[self class] allocWithZone:zone] init];
node.value = [self.value copyWithZone:zone];
node.left = [self.left copyWithZone:zone];
node.right = [self.right copyWithZone:zone];
return node;
}
这个例子有一些特别。由于 TreeNode 的实例变量仍然是 TreeNode。这里的拷贝行为将出现对 - (id)copyWithZone:(NSZone *)zone 的递归调用的。这时,效果上将会是一个完全拷贝。
但是,从 - (id)copyWithZone:(NSZone *)zone 的实现来看。任何一个对象的实例变量的拷贝行为都是由其自身如何实现 - (id)copyWithZone:(NSZone *)zone 所决定的。如果,TreeNode 包含了一个只实现了浅拷贝的实例变量。那么,对一个节点的完全拷贝了,就不是复制整个树了。这个例子说明,拷贝行为由于对象复杂的引用关系,也会变得极为复杂。如果,要搞清楚一个复杂对象的拷贝行为,需要顺着其对象引用链,逐个考察。NSCopying 协议并不保证某个对象拷贝行为具体会是什么样子。
下图展示了浅拷贝和深拷贝的区别:
Real-deep copy,完全拷贝
即保证对于被复制对象的每一层都是对象复制。在 Objective-C 中,这种拷贝行为,通常通过 NSKeyedUnarchiver 和 NSKeyedArchiver 来实现。实质是,先对对象进行序列化,再反序列化,这样就能创建出一个完全一样的对象。
对数组进行这个过程的代码:
NSArray arrayCopy = [NSKeyedUnarchiver unarchiveObjectWithData:[NSKeyedArchiver archivedDataWithRootObject:array]];
这个做法之所以奏效的原因是,对对象进行序列化,和反序列化,需要类实现 NSCoding 协议的两个方法。
//从coder中读取数据,保存到相应的变量中,即反序列化数据
-(id)initWithCoder:(NSCoder *)coder;
// 读取实例变量,并把这些数据写到coder中去。序列化数据
-(void)encodeWithCoder:(NSCoder *)coder;
这两个方法定义了类的序列化,和反序列化行为。和拷贝可以有含糊的空间不同。完全的序列化,需要存储对象所有的信息;完全的反序列化,需要取出原对象所有的信息。所以,如果这两个方法的实现是正确的。即对象引用链上的所有对象都处理得当。那么,执行序列化,再执行反序列化,确实就是一次完全拷贝。
当然,这个过程通常代价巨大。在一门编程语言中,一种拷贝行为,却需要通过序列化,和反序列化来完成。稍微深入思考,应该能感觉到这隐含了某些问题。这是因为,拷贝行为没有统一的定义。而序列化,和反序列化有着精确的定义,它们恰好又都是一个创建新对象的过程。这使得,在结果上,序列化,再反序列化的过程,和完全拷贝一样。
拷贝没有统一的定义除了完全拷贝代价巨大之外。在很多情况下,其实也无需拥有一个完全拷贝,就可以完成任务。这通常是,我们可以保证不去修改被拷贝的对象的情况下,拷贝对象持有指针副本,而不是完全的对象副本也没什么不可以的。但是,这需要我们自己维护这种正确性,通过代码逻辑防止副作用的发生。
拷贝没有统一的定义。这是一种基于现实情况的妥协和折衷。看起来,确实不得不这么做。但是,这却使得我们的程序运行环境出现了更巨大的复杂性。
总结
这篇文章主要讨论了以下三点:
- NSMutableCopying 是在一门可变的语言中追求不可变性的一个额外代价。
- NSCoying 是可变的一个额外的代价。
- 拷贝没有统一的定义,这是基于现实情况的妥协和折衷。
这三点已经可以简单反映拷贝的复杂性。这种复杂性,使得我们编写大规模的软件项目时,会遇到更多的困难。
能意识到这种复杂性的原因是,存在另外一条没有这种艰难的道路存在。走过那条路的人都感叹,风光旖旎。这条道路是:“函数式编程”。这篇文章 Swift 函数式编程-不变性 对函数式编程的不变性作了介绍。
但是,对于函数式编程。同样地也需要警惕:巨大优点通常伴随着沉重的代价。面向对象的这些缺点都是在发展了多年,经过了大规模的工业应用之后才发现的。函数式编程或许没有拷贝引入的这种复杂性。但我们并不确定,函数式编程是否有其他的问题。这需要另一次大规模的工业应用,但这种机会通常可遇不可求。