搬砖生涯中的吉光片羽
2016-12-06
吉光片羽
作为一个写移动应用的程序员,大部分时候都是在处理和用户界面相关的工作。无论是 iOS 还是 Android,系统都已提供了完备的 API。很多时候,工作就像是搬砖。我们使用到的组件,都像砖头一样,封装良好,易于堆砌。这当然是好事。因为,这使开发工作更为容易了。开发者可以脱离繁琐的细节,在系统的基础上,创造出精彩的应用;但另一方面,这也使得程序员的工作出现了异化。大部分现代程序员的工作,其实已不需要太多的抽象思维能力。只需要积累经验,磨砺技巧,增加对所工作的系统的熟悉程度,就可以完成绝大部分开发工作了。
抽象实际中遇到的问题,使用合适的数据结构和算法解决问题的机会并不多。当然,就更不用说创造一些新的数据结构和算法,解决新问题了。这样的工作,时间一长,就难免有些乏味。感觉思维游戏变成了体力劳动。
有时候,会羡慕和敬佩那些做理论研究的科学家。他们沉浸在高度抽象的思维中,做着各种各样的思维实验,或者说思维游戏。科学理论常常经历这样一个循环的过程:实践,观察,抽象,再实践。以实践为素材,通过抽象思维提炼出来的理论再次反哺实践时,常常表现出优雅的美感,以及惊人的力量。
在日常工作中,作为平常人,我们能体会到的和这种科学研究过程稍有类似的过程可能是:那些在书中学到的抽象的知识,优雅地解决了实际工作中的遇到的问题。这时,就能更深刻理解某种理论或者知识,稍稍体悟到思维结晶所表现出的美感。这种感觉就像在一片黑暗中触碰到了吉光片羽。
这种体会,在写 FRDIntent 的过程中,我稍微有过一次。向代码仓库提 PR 的瞬间,感觉很开心。所以,就写了一篇文章,记录一下这一刻愉快的心情。
也许,对于一些早已了解了这个知识的人而言,这是很平常的。对于我而言,当然也不仅仅是学习到了一个知识,也不仅仅是把学到的知识用上了。更重要的是,面对平庸,甚至苦闷的生活时,如何为自己寻找些许值得欣慰的东西 – 即黑暗中的吉光片羽呢?这些其实都可以是自己为自己定义的。如果,学习更抽象的理论知识,却指导了更底层的工作实践,这个过程能体会到美感和愉悦。那么,这就是一件有意义的事情。这些有意义的事情就值得反复去做,并体验这个过程所获得欣喜。
FRDIntent
FRDIntent 是一个用于处理 iOS 中页面调用的工具。可以用 FRDIntent 实现 iOS 项目中各个页面代码的解耦。
关于 FRDIntent 的详细介绍可以看以下两篇文章:
使用 FRDIntent 处理页面跳转,主要目的是解耦:即我们不再需要直接指明跳转目的页面的类,而是使用 url 来标识需要跳转到的页面。那么,这就需要提供一张以 url 查询 view controller 的表。这是 FRDIntent 的一个重要部分。这篇文章就主要聊聊 FRDIntent 中的这个部分:使用何种数据结构存储 url 到 view controller 之间的映射关系?
为何不用字典?
存储对应关系一般都可以用字典。Swift 中的字典使用哈希表实现的。FRDIntent 这个例子中,url 作为键值 key,view controller 类型信息作为实际存储的值 value。但在 FRDIntent 中,查询操作还有一些更复杂的需求:
- 支持模式匹配。即 “/user/:userID” 这样的 url,是可以匹配到以 “/user/123” 为 key 的查询。
- 支持模糊匹配。在没有和待查询的 key 完全匹配的情况下,返回一个最接近的 key 的 value。例如,在没有 key 和 “/user/:userID/error” 完全匹配的情况下,可以返回以一个最接近的(如果表中有的话) “/user/123/” 为 key 所对应的 value。
这两个需求都暗示了这个对应关系的键值 key 是有顺序结构信息的。哈希表本质上将键值 key 作为一个整体考虑,会使用哈希函数将不同的 key 计算为一类哈希值。所以,使用哈希表实现的字典其实很难完成以上两个需求。
PathNodeSearchTree
在最开始实现这个功能时,我直觉地建了一棵建搜索树。表示这棵搜索树的类的名字为 PathNodeSearchTree。在这棵树中,每个 url path 都作为这棵树的一个结点的键值 key。从根结点遍历到某个结点,所有经过的结点的键值 key 按访问顺序连接起来就可以形成一个 url,这个 url 才是该结点正真的键值 key。
树结构完整保留了键值 key 的顺序结构信息。所以,在应对对 key 的部分信息进行模式匹配这种的需求时,使用这棵搜索树可以很轻松自如地完成。
Trie
后来,我看书发现这棵搜索树其实就是 Trie。
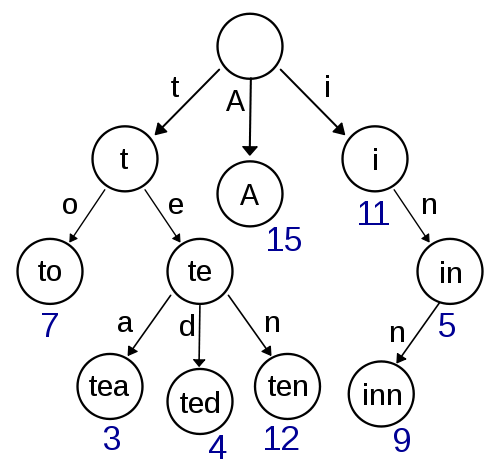
这一段文字摘自中文维基百科:
在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。 与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。 一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
我学习了一下 Trie。前人当然已经做了很充分的研究,并且已经存在很完整的 Trie 的各种语言的实现。所以,我参考了经典实现,改写了一下原有的稍显粗糙的实现,剔除了不必要的细节。
最后提了这个 PR: Extract the data structure of Trie,包括了这些内容:
- 把 Trie 这个数据结构提炼了出来;
- 将基础数据结构 Trie 和业务上对基础数据结构的封装使用 RouteManager 做了明晰的分隔。
改完之后,我发现代码确实清晰简洁了不少。
- 注册 url 对应的 view controller,就是在 Trie 中插入一条以 url 为 key,view controller 类型为 value 的记录。
- 查找 view controller,就是在 Trie 中以 url 为 key,查询 view controller 信息。
- 模式匹配只需要对经典的 Trie 查找操作做简单的修改便轻松实现了。
算法的时间复杂度
创建 Trie 时间复杂度是 O(n*m),其中 n 是 url 的数量;m 是 url 平均拥有的 path 的数量。查找和插入的时间复杂度是 O(m)。因为,查找需要和 url path 数量相同的 m 步。插入过程和查找类似,区别只是在没有结点时,需要做新建结点的操作。
用哈希表实现的字典的插入和查找的时间复杂度都是常数的 O(1)。
Trie 的查找和插入的时间复杂度较字典要稍微高一点。
算法的空间复杂度
Trie 的空间复杂度稍微复杂一些,其空间复杂度是结点数量:O(k),其中 k 是所有 url 的不同的 path 总数。
使用哈希表的实现的字典在这个场景中的空间复杂度是 O(n),其中 n 是 url 的数量。
同样,Trie 需要的空间也比字典多。特别是在,url 都有较多 path,且基本没有相同前缀的情况下。因为每个 url path 都要占据一个结点。这种情况下,代表了完整有效的 url 的结点较少,大部分节点用于表示有效 url 的前缀。这种情况下,也可以说这棵 Trie 树比较稀释。Trie 越稀释,表示它的空间复杂度越大。
总结
虽然比较其字典而言,Trie 的时间和空间复杂度都要差一点,但其实还算不错。在我们的场景下也足够用了。因为,我们不会有太长的 url。注册的 url 数量最多也就是千这个数量级。但 Trie 这个数据结构却很适合维护以像 url 这种有顺序结构信息为键值的对应关系。
所以,对于 FRDIntent 而言,使用 Trie 存储 url 和 view controller 的对应关系应该是一个合适的选择。